目录
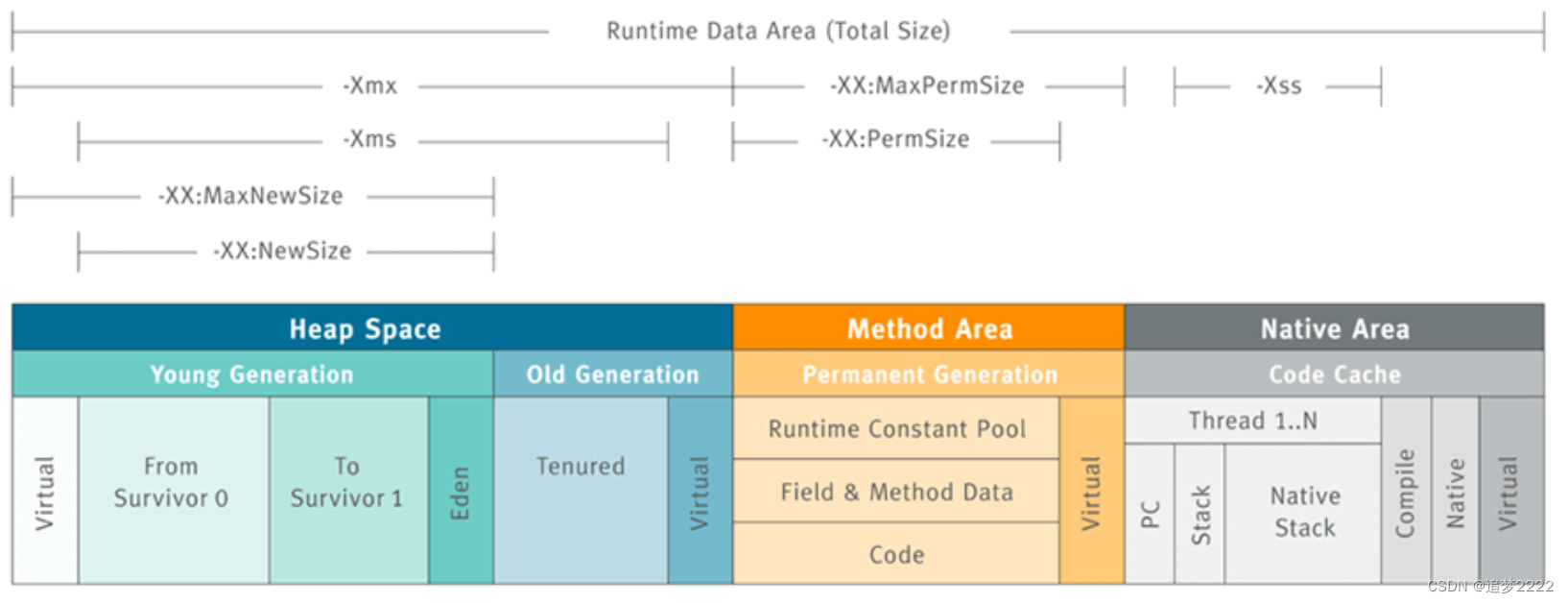
1 C/C++的内存分布
2 C语言的内存管理
3 C++的内存管理
4 operator new 和 operator delete
5 定位new
1 C/C++的内存分布
语言不同,内存分布是相同的,对于局部变量都是放在栈上,全局变量都是放在静态区(数据段),动态开辟的都是从堆中开辟,const修饰的变量也是都放在常量区(代码段)
这里试试手:
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}globalVar在哪里?staticGlobalVar在哪里?staticVar在哪里? localVar在哪里?num1 在哪里?char2在哪里? *char2在哪里?pChar3在哪里?*pChar3在哪里? ptr1在哪里? *ptr1在哪里?
A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)
globalVar是全局变量,所以在静态区,C;
StaticGlobalVar是被static修饰的变量,所以在静态区,C;
StaticVar也是被static修饰的,所以在静态区,C;
localVar是局部变量,所以在栈,A;
num1是地址,在栈上,A;char 2也是地址,在栈上,
A;*char2是常量字符串的第一个字符,所以在常量区,D;
pChar3是地址,栈上,A;
*pChar3同*char2,在常量区,D;
ptr1是地址,栈上,A;
*ptr1是动态开辟的第一个空间的元素,堆上,B。
2 C语言的内存管理
C语言中的内存是用函数的形式进行管理的,涉及的函数是malloc realloc calloc free,均被包含在头文件stdlib里面,malloc函数和calloc函数的最大区别就是是否初始化的问题,realloc是用来扩容,使用完会自动是空间,free是释放空间。
似乎看起来比较完美了,但是为什么C++有单独的内存管理方式呢?
这是因为:
int main()
{
int* pa = (int*)malloc(sizeof(int) * 10);
free(pa);
return 0;
}malloc等函数只能用来申请内置类型的空间,对于自定义类型就没有办法,顺便提一句,涉及内存管理的时候,最好注意有没有内存泄露的问题,内存泄露是慢性病,很严重的喔。
那么,C++就引入了不同的方式进行内存管理,其实C语言的内存管理的方式在C++里面也是可以使用的,但是局限性比较大,当我们学会后面的内存管理方式之后,就把malloc函数等放在一边吧
3 C++的内存管理
在C++中内存管理是使用new 和 delete来实现的,这两个都是C++中的标识符,和C语言不同的是C++实现内存管理不是用的函数。
首先,对于内置类型来说:
int* p1 = new int;这写法等价于:
int* p1 = (int*)malloc(sizeof(int) * 1);一下就简洁了,与calloc不同的是,这样不能进行初始化,那么要进行初始化可以在后面加括号:
int* p1 = new int(1);通过解引用打印出来也是1,与calloc不同的是初始化可以任意初始化,calloc只能初始化为0。
那么开辟一个数组使用到的是方括号:
int* pa = new int[10];这种写法是开辟了一个大小为40字节的数组,初始化的方式是使用花括号:
int* pa = new int[10]{1,2,3,4};这里和数组是一样,如果不是初始完全的话,那么剩下的部分就会自动初始化为0。
既然是开辟空间,方括号里面的也可以是变量,同malloc函数一样,可以使用变量:
int n = 10;
int* pa = new int[n]{1,2,3};当然,C++引入了new和delete可不是为了内置类型的,是为的自定义类型:
这里使用类A介绍:
class A
{
public:
A(int n)
:_a(n)
,_b(n - 1)
{
cout << "int n" << endl;
}
A(int a, int b)
:_a(a)
,_b(b)
{
cout << "int a, int b" << endl;
}
~A()
{
_a = _b = -1;
cout << "~A" << endl;
}
private:
int _a;
int _b;
};3.1 new
使用:
A* pA = new A;//开辟一个A
A* pB = new A(0);//对pB对象初始化
A* pC = new A[10];//开辟10个对象的空间
A* pD = new A[10]{1,2,3,{1,3}};//初始化对象
对于自定义类型来说,需要注意的是初始化其实使用了隐式类型转换,对于多参数的对象来说,就是花括号里面套一个花括号就可以了。
这里可能有个问题就是A* pB = new A(0)给的是匿名对象吗?并不是,因为匿名对象的生命周期只有这一行,后面就直接析构了,但是这里没有,所以不是匿名对象。
这是开辟空间的用法,你如果认为只有这么简单就错辣!
new比malloc高级在于,new不仅仅包含了malloc,我们逐一介绍,这里不卖关子,直说了就:
new = malloc + 抛异常 + 构造函数,其中malloc + 抛异常 = operator new,大概是可以这样理解的。
首先,new一个自定义类型的时候是会自动调用对应的构造函数的: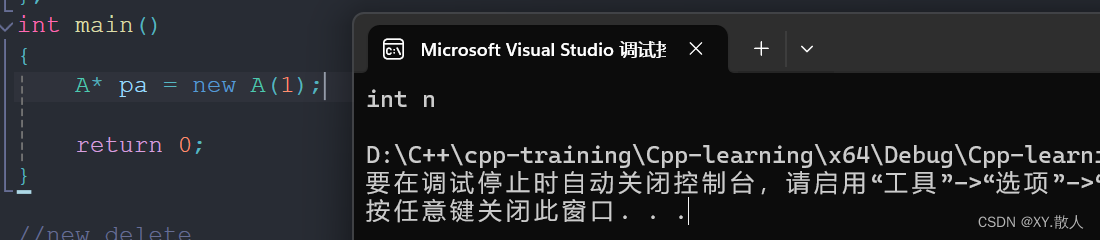
new一个的时候如果内存足够,就会调用对应的构造函数,光是能调用对应的构造函数,就可以节省很多事:
struct ListNode
{
//struct ListNode* _next;
ListNode* _next;
int _val;
ListNode(int val)
:_next(nullptr)
,_val(val)
{}
};
void Func()
{
ListNode* n1 = new ListNode(1);
ListNode* n2 = new ListNode(2);
ListNode* n3 = new ListNode(3);
n1->_next = n2;
n2->_next = n3;
delete n1;
delete n2;
delete n3;
}既然能调用构造函数,手搓链表的时候只能说太爽了,至于struct写不写看文件后缀,C++中里面的那个struct可以不用写。
int main()
{
A* pa = new A(0);
return 0;
}我们再来看看这段代码的反汇编:

F11调试之后,跳转了几次来到了这里,就会发现,new的底层调用的其实是malloc,所以new是对malloc的一个封装,跳转之前我们还可以看到:
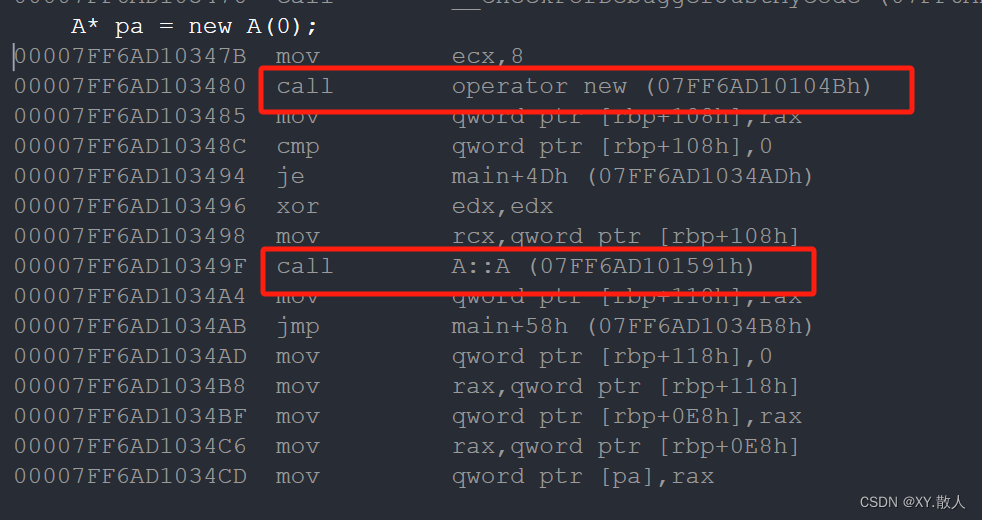
有operator new和A::A,先进入了operator new就会发现里面有我们熟悉的malloc,后面再调用了构造函数。
为什么说new用来手搓链表就很爽,因为我们不用没开辟一个就去assert一下,new里面的抛异常会帮我们解决;
因为抛异常是后面的知识了,这里简单介绍,在C语言中报错是通过返回错误码,比较暴力,在C++中有一种温和的报错方式就是抛异常,通过try - catch ,比如我一次性开辟很大的空间,系统分配的内存不够了,那么try-catch就会起作用,程序运行完毕会打印一行字,告诉你有错误,new里面的抛异常就是为了防止开辟空间不够,因为链表每次开辟一个节点就要检查是否为空,new底层中的malloc开辟之后,抛异常直接就帮忙解决了空指针的问题(因为malloc函数开辟失败返回的是空指针)。
总结来说就是:new = malloc + 抛异常 + 构造函数,new是对malloc的封装,对内置类型来说new和malloc没有区别,对自定义类型来说new不仅可以开辟空间,还可以抛异常并且调用对应的构造函数。
3.2 delete
同C语言,开辟了空间,使用完就要还给操作系统,C语言中使用的是free,在C++中使用的是delete,delete = operator delete+ 析构,而operator delete最终是通过free实现的:
这里当我们进入到operator delete的汇编就可以发现:
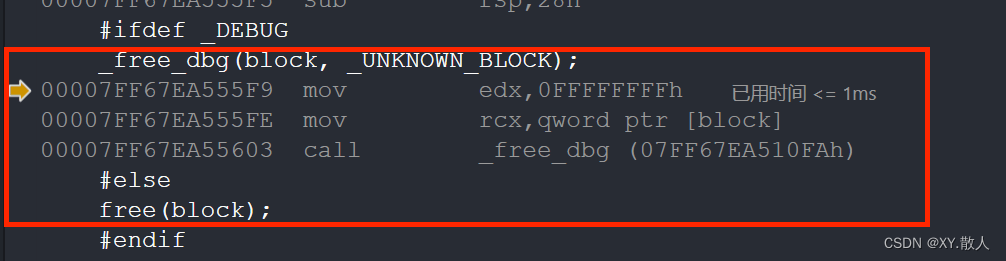
最后调用的其实就是free,这里是free的宏,即operator delete最终使用free释放。
delete的大致使用如下:
int main()
{
A* pa = new A(0);
A* pb = new A[10]{1,2,3,4};
delete pa;
delete[] pb;
return 0;
}对于pb来说,我们开辟了10个A类型的空间,也就是我们开辟了80个字节,delete就会释放这么多字节,但是!
当我们显式调用了析构函数之后,真的只开辟了80个字节吗?
在2019中,我们进入到operator new中就可以看到:

我们明明只要40个字节,却多开了4个字节,但是当我们注释掉析构函数之后,我们再去调试,就会发现size变成了40,也就是有没有显式调用析构函数会影响实际开辟的空间大小,这里我们再引入一个点:
C语言和C++中的内存管理混用可以吗?
用malloc函数开辟的我用delete,用new的我用free,你说可行吗?实际上对于内置类型来说是没有问题的,因为不会涉及多开空间的问题,也就不会涉及越界的问题,那么对于自定义类型来说:
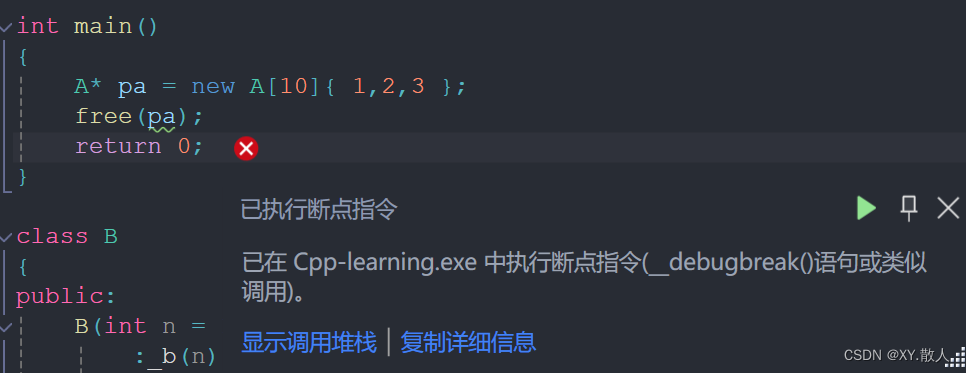
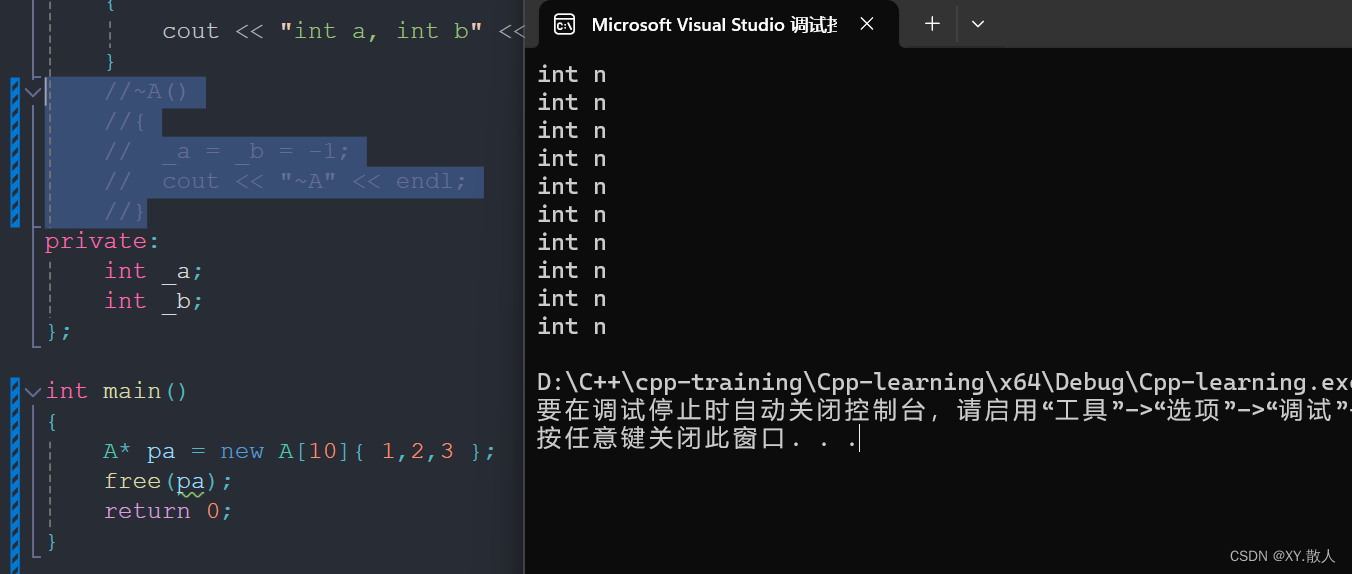
当我们显式调用了析构函数,使用free就会出问题,其实不管是free还是delete都会出问题: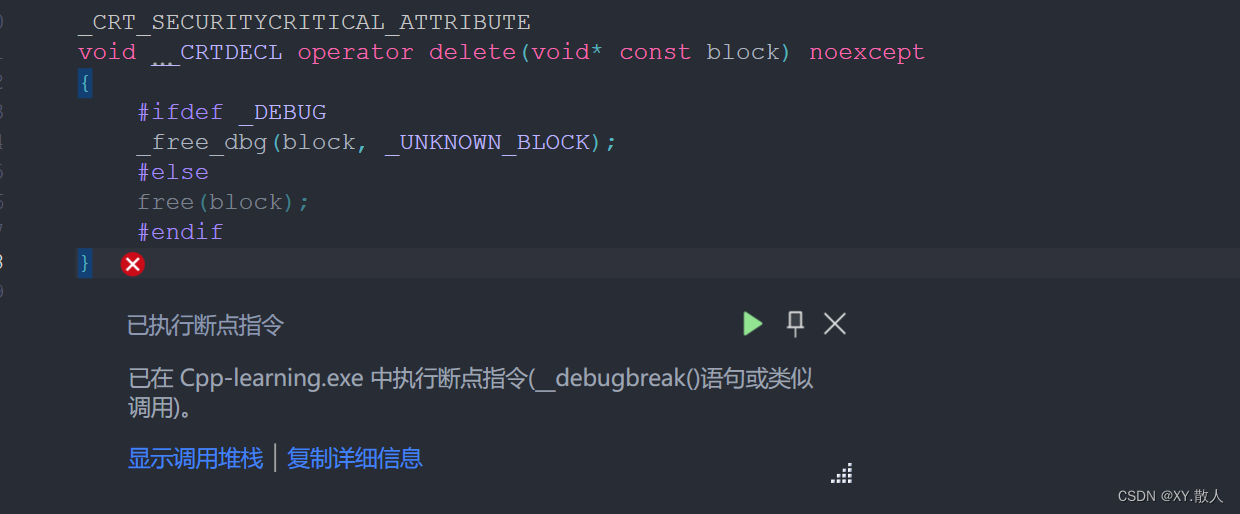
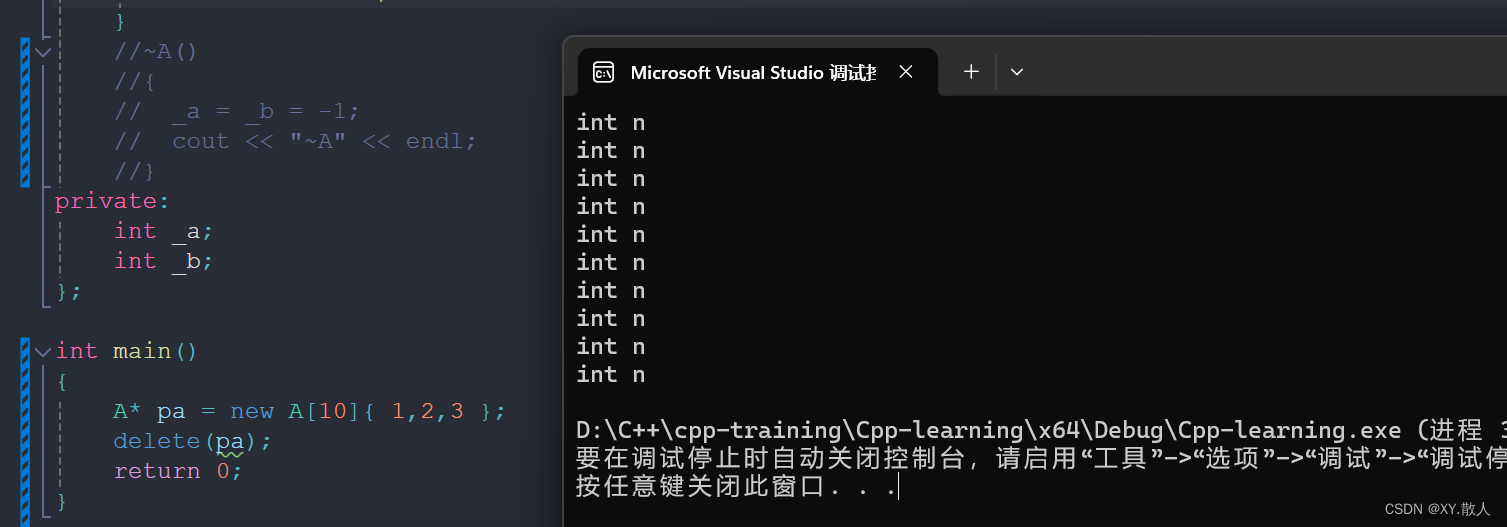
其中的缘由就是多开的4个空间是用来干嘛的,当显式调用析构函数之后,多开辟的空间就是用来记录有多少个空间需要被析构,是一个数字用来记录,那么就多开了一个整型,所以会多4字节,如果没有显式调用析构就不会,显式调用就相当于告诉编译器我有这么多空间需要销毁,你记得数数。
那么为什么会出现越界的问题?
因为开辟了多少空间,delete[] 就知道要销毁这么多空间,在delete[]对应的汇编中有一条语句是回退4个字节,所以delete[]操作的时候就不会出现越界的问题,对于free delete来说没有回退的指令就会出现越界的问题,这也就是为什么不要混用的原因,挺容易出现幺蛾子的。
delete是operator delete + 析构,那么有没有想过,析构的是哪里?operator delete的free是free的哪里呢?
这个问题是比较简单的,不卖管子了就,free是free掉指针指向的区域,析构是完成资源清理工作(如果有资源需要清理的话),有点像两个栈实现队列的那种说法。
4 operator new 和 operator delete
其实在上面new和delete的介绍已经把这两个介绍的差不多了,这里补充一些点即可。
operator new 和 operator delete是全局函数,不是C++中的标识符,我们通过它们的定义就可以知道 operator new 是调用的malloc实现的开辟空间,operator delete是调用的free来释放的空间,
既然是全局函数,意味我们可以显式的调用:
显式调用的情况,operator new和malloc函数的用法是一样的,都不能进行初始化,operator delete使用和free是一样的:
int main()
{
int* p1 = (int*)operator new(sizeof(int) * 10);
A* pa = (A*)operator new (sizeof(A) * 10);
operator delete(p1);
operator delete(pa);
return 0;
}它们主要的内容还是前面讲的。
5 定位new
定位new这里了解一下就行了:
使用格式: new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
int main()
{
A* p2 = (A*)operator new(sizeof(A));
new(p2)A;
A* p3 = (A*)operator new(sizeof(A));
new(p3)A(1);
return 0;
}我们平常显式调用析构函数是没有问题,但是如果想显式调用构造函数就有问题了,构造函数是初始化用的,也就是一旦对象实例化了,就会自动的调用对应的构造函数,像上面的情景,指针指向一块空间,我们相对它进行初始化不能直接显式的调用构造函数,这里就需要用定位new了,格式如上,如果是多个对象,调用构造可以这样:
int main()
{
A* p4 = (A*)operator new(sizeof(A) * 10);
for (int i = 0; i < 10; i++)
{
new(p4 + i)A{ i };
}
A* p5 = (A*)operator new(sizeof(A) * 10);
new(p5)A[5]{ 1,2,3,4,5 };
return 0;
}有两种初始化方法,比较推荐的是for循环,因为好控制,一旦空间大了,比如1000个,一个一个写显然是不可能的,所以一般用for循环。
定位new一般是用于内存池的情况,因为从内存池分配出来的空间都是没有初始化的,所以需要用到定位new,但是更多的细节放在后面介绍,是计算机网络的知识了。
感谢阅读!